Análisis de la exposición poblacional a peligros de inundación en el Partido de La Plata
Author
Mgstr. Nissim Lebovits, Dr. Arq. Juan Carlos Etulaín y Est. Celeste Duarte
4.1 Resumen ejecutivo
Este análisis demuestra que el uso de datos de huellas de edificaciones mejora significativamente tanto la precisión como la comprehensividad del mapeo de riesgo en asentamientos informales cuando se compara con la interpolación areal y los datos del RENABAP. Este enfoque basado en edificaciones no solo proporciona estimaciones más precisas y actualizadas que los métodos tradicionales de interpolación areal, sino que también demuestra la necesidad urgente de actualizar los registros oficiales de barrios populares, representando una herramienta esencial para comprender la verdadera magnitud de la población en riesgo y para la planificación efectiva de políticas públicas de diversa naturaleza.
Los datos de huellas de edificaciones nos permiten realizar evaluaciones mucho más precisas de la exposición en barrios populares y revelan una subestimación crítica en los datos oficiales del RENABAP, identificando aproximadamente 41.575 edificaciones faltantes que representan entre 137.000 y 229.000 personas no contabilizadas. La comparación metodológica demuestra que nuestro enfoque aporta un mayor número total de población expuesta (aproximadamente el doble de edificaciones que los datos oficiales) pero una menor proporción de exposición relativa (23,5% vs 26,3%), lo que demuestra que la interpolación areal sobrestima la exposición al asumir distribución uniforme de la población, mientras que nuestro método más preciso es más confiable para la evaluación de riesgos.
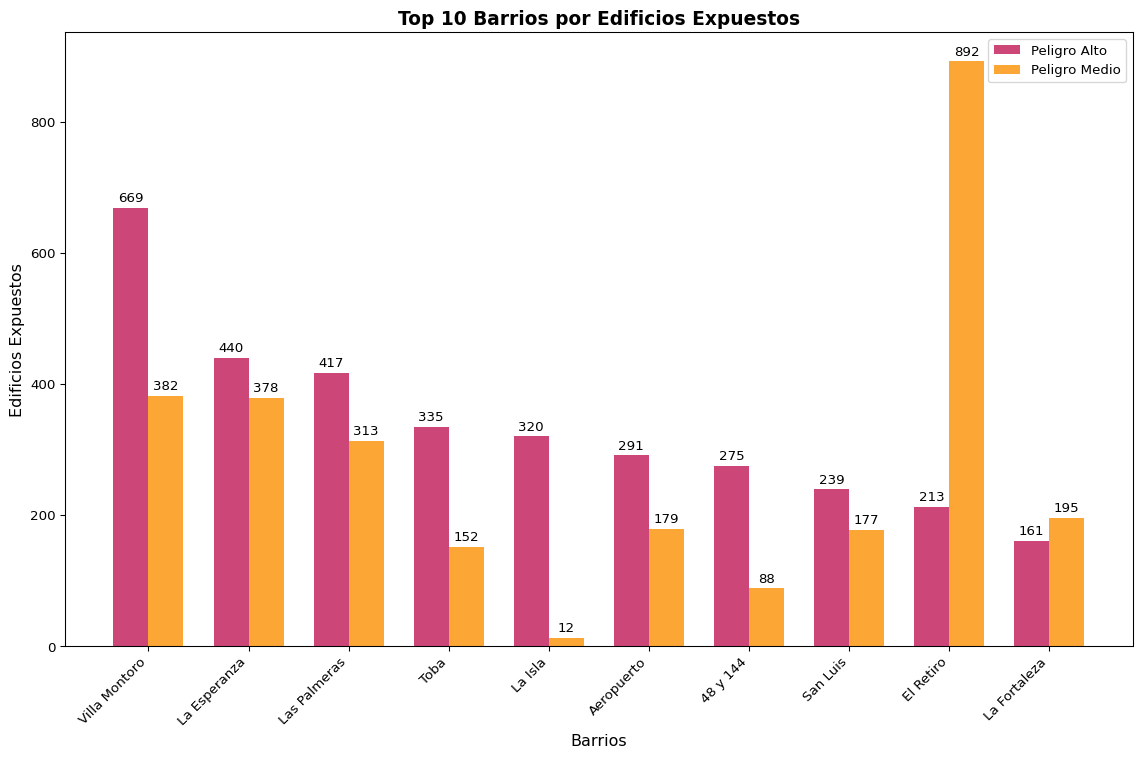
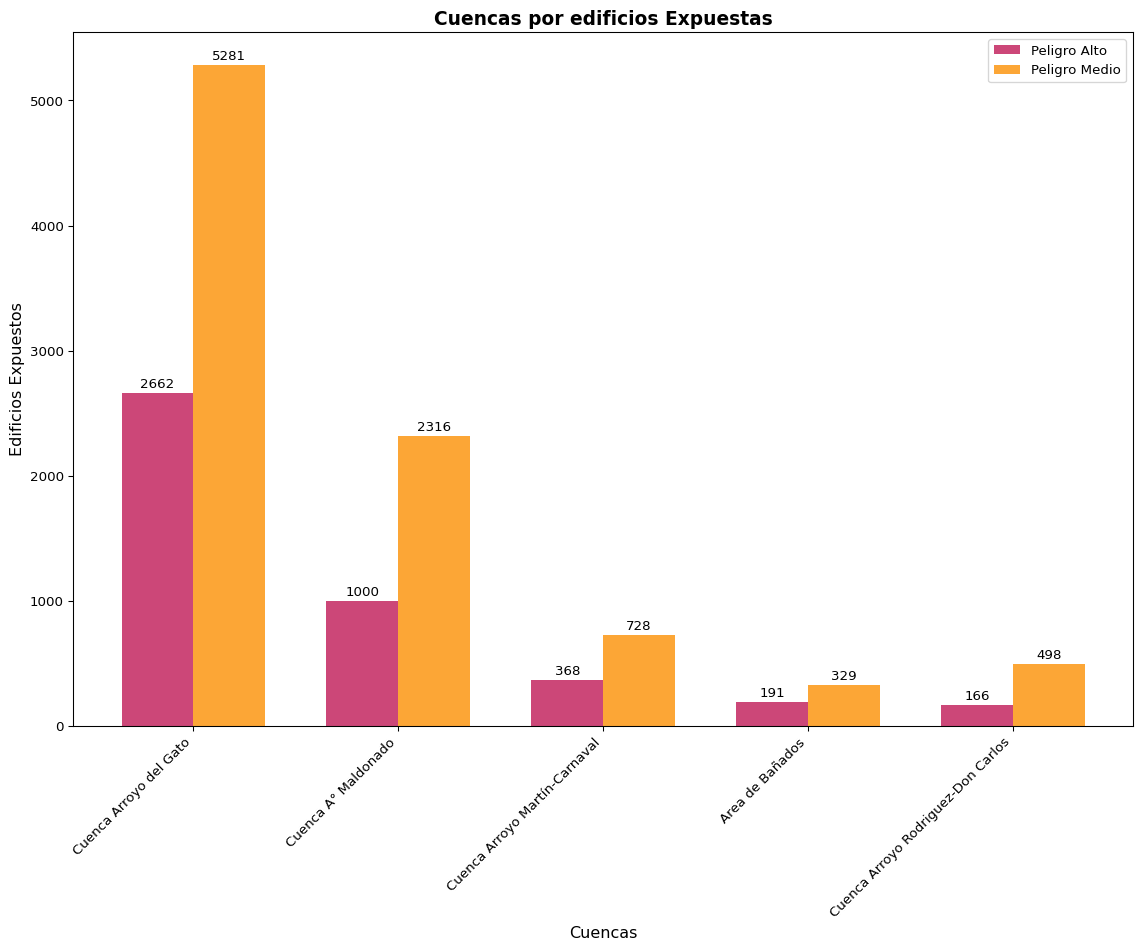
En los barrios populares de La Plata se identifican 17.014 edificaciones expuestas a peligro de inundación ante el escenario de PMP, lo que representa el 23,5% del total de edificaciones en barrios populares. De estas, 6.112 edificaciones se encuentran en zonas de peligro alto y 10.902 en zonas de peligro medio. Los barrios con mayor exposición incluyen: Villa Montoro con 669 edificaciones expuestas a peligro alto (21,7% del barrio), seguido por La Esperanza con 440 edificaciones (16,3%), Las Palmeras con 417 (33,7%), Toba con 335 (67,7%), y La Isla con 320 edificaciones (96,4%). A nivel de cuencas hidrográficas, Cuenca Arroyo del Gato concentra la mayor exposición con 7.943 edificaciones expuestas (2.662 a peligro alto y 5.281 a peligro medio), seguida por Cuenca A° Maldonado con 3.316 edificaciones (1.000 alta, 2.316 media) y Cuenca Arroyo Martín-Carnaval con 1.096 edificaciones (368 alta, 728 media).
El análisis comparativo de diferentes períodos de retorno revela que la elección del período genera diferencias significativas en las estimaciones de exposición, siendo crucial para determinar qué áreas priorizar para la reubicación de residentes en asentamientos informales. La exposición calculada con PMP puede ser hasta 13,0 veces mayor que con un período de retorno de 25 años, lo que tiene consecuencias significativas para la evaluación de políticas públicas como la reubicación de poblaciones.
Este proyecto se propone tres objetivos principales:
Identificar metodologías más precisas para evaluar la población expuesta en barrios populares según lo determina el RENABAP Se procura desarrollar y aplicar técnicas de análisis espacial que superen las limitaciones de la interpolación areal tradicional, utilizando datos de huellas de edificaciones para obtener estimaciones más precisas de la exposición ante el peligro de inundación en los barrios populares, y demostrar las limitaciones significativas de los datos oficiales del RENABAP en relación al número de viviendas y población.
Aportar y precisar el mapeo del riesgo hídrico en el Partido de La Plata Se pretende mejorar la comprensión de la distribución espacial del riesgo de inundación mediante el análisis de la exposición de viviendas vulnerables que forman parte de los barrios populares registrados por el RENABAP, proporcionando información detallada para la toma de decisiones a nivel municipal y la planificación de políticas de reducción de riesgo.
Poner en cuestión las recurrencias utilizadas para el cálculo del riesgo por inundaciones, en función de la política pública a implementar Evaluar críticamente los períodos de retorno utilizados en los modelos de peligrosidad para la construcción de los mapas de riesgo y examinar la importancia de la precisión de los datos considerados en función de la política pública a implementar.
Mostrar código
import matplotlib.pyplot as pltfrom io import StringIOfrom shapely.geometry import boximport geopandas as gpdimport requestsimport osimport itablesfrom itables import showfrom IPython.display import HTML, displayfrom matplotlib_map_utils import north_arrow, scale_bar, ScaleBarfrom matplotlib.patches import Patchfrom shapely.ops import unary_unionimport contextily as cx# Global settings for international number formattingimport localeimport pandas as pdimport numpy as np# Set locale for international number formatting (period for thousands, comma for decimal)try: locale.setlocale(locale.LC_ALL, 'es_AR.UTF-8')except locale.Error:try: locale.setlocale(locale.LC_ALL, 'es_ES.UTF-8')except locale.Error: locale.setlocale(locale.LC_ALL, '')# Set pandas options for international formattingpd.set_option('display.float_format', lambda x: f'{x:,.1f}'.replace(',', '.').replace('.', ',', 1))# Helper function to format numbers with international formatting (periods for thousands, commas for decimals)def format_number(num, decimals=None):if decimals isNone:# Integer formatting - periods for thousands separatorsreturnf"{num:,}".replace(",", ".")else:# Decimal formatting - periods for thousands, commas for decimals formatted =f"{num:,.{decimals}f}"# Split by decimal point parts = formatted.split(".")iflen(parts) ==2:# Add periods for thousands in integer part, keep comma for decimal integer_part = parts[0].replace(",", ".")returnf"{integer_part},{parts[1]}"else:# No decimal part, just add periods for thousandsreturn parts[0].replace(",", ".")from utils.utils import ( add_scale_bar_and_north_arrow, add_basemap, add_boundary_outline, create_consistent_map, wfs_to_gdf, fetch_buildings,)ScaleBar.set_size(size="md")# Configure Argentine Spanish for itablestry: spanish_url ="https://cdn.datatables.net/plug-ins/2.3.3/i18n/es-AR.json" response = requests.get(spanish_url) response.raise_for_status() spanish_config = response.json() itables.options.language = spanish_configexceptException:pass# Configure smaller font size for all itablescss =""".dt-container { font-size: small;}"""display(HTML(f"<style>{css}</style>"))# Helper function to round numeric columns for displaydef round_numeric_columns(df, decimals=0):"""Round all numeric columns in a DataFrame to specified decimal places.""" df_display = df.copy() numeric_columns = df_display.select_dtypes(include=[np.number]).columns df_display[numeric_columns] = df_display[numeric_columns].round(decimals)return df_displaydef add_scale_bar_and_north_arrow( ax, location="upper right", scale_color="black", arrow_color="black", length=None):"""Add a scale bar and north arrow to the map using matplotlib_map_utils."""# Add scale bar using matplotlib_map_utils ScaleBar class with ticks style scale_bar( ax=ax, location="upper left", style="ticks", bar={"projection": "EPSG:3857","tickcolors": scale_color,"basecolors": scale_color,"minor_type": "none","length": length, }, labels={"style": "first_last"}, )# Add north arrow using matplotlib_map_utils north_arrow( ax, location=location, scale=0.3, # Small size rotation={"degrees": 0}, base={"facecolor": "none", "edgecolor": arrow_color, "linewidth": 1}, fancy=True, shadow=True, label=False, # Hide the "N" text )def setup_base_map( use_crs, figsize=None, bounds=None, boundary_gdf=None, padding_x=None, padding_y=None):"""Create figure and set up basic map boundaries with padding."""if figsize isNone: figsize = DEFAULT_FIGSIZEif padding_x isNone: padding_x = MAP_PADDINGif padding_y isNone: padding_y = MAP_PADDINGif bounds isNoneand boundary_gdf isnotNone: bounds = boundary_gdf.total_bounds# Convert bounds to Web Mercator for basemap compatibilityif bounds isnotNone:# Create a temporary GeoDataFrame with the bounds to reproject temp_bounds = gpd.GeoDataFrame( geometry=[box(bounds[0], bounds[1], bounds[2], bounds[3])], crs=use_crs ) bounds_3857 = temp_bounds.to_crs(WEB_MERCATOR_CRS).total_boundselse: bounds_3857 = bounds fig, ax = plt.subplots(figsize=figsize) ax.set_xlim(bounds_3857[0] - padding_x, bounds_3857[2] + padding_x) ax.set_ylim(bounds_3857[1] - padding_y, bounds_3857[3] + padding_y)return fig, axdef create_consistent_map(title, crs, boundary_gdf=None, bounds=None, attribution=None, scalebar_length=None):"""Create a map with consistent styling and basemap.""" fig, ax = setup_base_map(crs, bounds=bounds, boundary_gdf=boundary_gdf) add_basemap(ax, attribution=attribution) add_scale_bar_and_north_arrow(ax, length=scalebar_length) add_boundary_outline(ax, boundary_gdf) ax.set_title(title, fontsize=16, fontweight="bold", pad=20) ax.set_axis_off()return fig, ax# =============================================================================# CONSTANTES Y CONFIGURACIÓN# =============================================================================USE_CRS ="EPSG:5349"# POSGAR 2007 / Argentina 4WEB_MERCATOR_CRS ="EPSG:3857"# visualizationWGS84_CRS ="EPSG:4326"# for API callsBASE_PATH ="/home/nissim/Documents/dev/fulbright/ciut-riesgo"DATA_PATH =f"{BASE_PATH}/notebooks/data"PELIGRO_PATH =f"{DATA_PATH}/la_plata_pelig_2023_datos_originales.geojson"PARTIDOS_PATH =f"{DATA_PATH}/pba_partidos.geojson"CUENCAS_PATH =f"{BASE_PATH}/notebooks/cuencas_buenos_aires.geojson"BUILDINGS_PATH =f"{BASE_PATH}/notebooks/buildings_filtered.parquet"RENABAP_URL = ("https://www.argentina.gob.ar/sites/default/files/renabap-2023-12-06.geojson")PARTIDOS_WFS_URL ="https://geo.arba.gov.ar/geoserver/idera/wfs"CUENCAS_API_URL ="https://services1.arcgis.com/atxllciEI8CHWvwW/ArcGIS/rest/services/Cuencas_BuenosAires_2023/FeatureServer/0/query"# Basic visualization settings (only for repeated values)DEFAULT_FIGSIZE = (12, 10)MAP_PADDING =500PLASMA_CMAP = plt.cm.plasma# Color schemes for visualizationPELIGROSIDAD_COLORS = {"alta": PLASMA_CMAP(0.5),"media": PLASMA_CMAP(0.8),}PELIGROSIDAD_LEGEND = [ Patch(facecolor=color, label=label) for label, color in PELIGROSIDAD_COLORS.items()]# Eje mapping for watershed analysisEJE_MAPPING = {"noreste": ["Area de Bañados", "Cuenca Arroyo Rodriguez-Don Carlos"],"noroeste": ["Cuenca Arroyo Martín-Carnaval", "Cuenca Arroyo Pereyra"],"central": ["Cuenca Arroyo del Gato"],"sudoeste": ["Cuenca A° Maldonado", "Cuenca Río Samborombón"],"sudeste": ["Cuenca Arroyo El Pescado"],}# =============================================================================# DATA LOADING AND PREPROCESSING# =============================================================================response = requests.get(RENABAP_URL)renabap = gpd.read_file(StringIO(response.text))renabap_pba = renabap[renabap["provincia"] =="Buenos Aires"]renabap_pba = renabap_pba.to_crs(USE_CRS)if os.path.exists(PARTIDOS_PATH): partidos = gpd.read_file(PARTIDOS_PATH)else: partidos = wfs_to_gdf( wfs_url=PARTIDOS_WFS_URL, layer_name="idera:Departamento", srs="EPSG:5347", ) partidos.to_file(PARTIDOS_PATH, driver="GeoJSON")partidos = partidos.to_crs(USE_CRS)la_plata = partidos[partidos["fna"] =="Partido de La Plata"]# Obtener la geometría principalmain_geom = la_plata.geometry.iloc[0]# Si es un MultiPolygon, mantener solo el polígono más grande (el partido principal)# Esto elimina la pequeña isla que aparece en los datosif main_geom.geom_type =="MultiPolygon":# Obtener todos los polígonos y mantener el que tenga mayor área largest_polygon =max(main_geom.geoms, key=lambda p: p.area) la_plata = la_plata.copy() # Create a copy to avoid SettingWithCopyWarning la_plata.loc[la_plata.index[0], "geometry"] = largest_polygonla_plata_bbox = la_plata.geometry.iloc[0]peligro = gpd.read_file(PELIGRO_PATH)peligro = peligro.to_crs(USE_CRS)peligro = peligro[peligro["PELIGROSID"] !="baja"]peligro_bounds = peligro.total_boundspeligro_bbox = box(*peligro_bounds)peligro_la_plata = peligro.clip(la_plata)peligro_clipped_3857 = peligro_la_plata.to_crs(WEB_MERCATOR_CRS)renabap_pba_intersect = renabap_pba[ renabap_pba.geometry.intersects(la_plata_bbox)].copy()if os.path.exists(CUENCAS_PATH): cuencas = gpd.read_file(CUENCAS_PATH)else: params = {"where": "1=1", "outFields": "*", "f": "geojson"} cuencas_response = requests.get(CUENCAS_API_URL, params=params)withopen(CUENCAS_PATH, "w", encoding="utf-8") as f: f.write(cuencas_response.text) cuencas = gpd.read_file(StringIO(cuencas_response.text))cuencas = cuencas.to_crs(USE_CRS)cuencas = cuencas.clip(la_plata)# Map watershed names to axes based on the EJE_MAPPINGcuencas["eje"] = ( cuencas["Cuenca"] .map( { cuenca: ejefor eje, cuencas_list in EJE_MAPPING.items()for cuenca in cuencas_list } ) .fillna("otro"))# Calculate total area of RENABAP settlements in hectares (POSGAR projection is in meters)renabap_total_area_ha = ( renabap_pba_intersect.geometry.area.sum() /10000) # Convert m² to hectaresla_plata_area_ha = la_plata.geometry.iloc[0].area /10000percentage_coverage = (renabap_total_area_ha / la_plata_area_ha) *100# Get common bounds for all mapscommon_bounds = la_plata.total_bounds# Intersect settlements with hazard zonessettlement_hazard = gpd.overlay(renabap_pba_intersect, peligro, how="intersection")settle_hazard_cuencas = gpd.overlay( settlement_hazard, cuencas, how="intersection", keep_geom_type=True)if os.path.exists(BUILDINGS_PATH): buildings = gpd.read_parquet(BUILDINGS_PATH)else: buildings = fetch_buildings(la_plata.buffer(500))la_plata_buffered = la_plata_bbox.buffer(500)buildings_proj = buildings.to_crs(USE_CRS)buildings_proj = buildings_proj[buildings_proj.geometry.intersects(la_plata_buffered)]
4.3 Fuentes de datos
4.3.1 RENABAP
El Registro Nacional de barrios populares (RENABAP), coordinado por la Subsecretaría de Integración Socio Urbana, sistematiza la información sobre los barrios populares en Argentina.1 El registro incluye estimaciones de población, delimitaciones geográficas y datos sociodemográficos, obtenidos a través de relevamientos territoriales realizados desde 2016 por equipos conformados por organizaciones sociales y vecinos de los barrios.
Este relevamiento de viviendas familiares se lleva a cabo a través de encuestas domiciliarias en los barrios populares registrados. La metodología combina el trabajo territorial con herramientas digitales, como aplicaciones móviles de geolocalización, escaneo de DNI, grabación de encuestas y cartografía editable. Cada polígono barrial se subdivide en manzanas, lotes y edificaciones y se completa una ficha por cada vivienda habitada. Los datos son validados con organismos oficiales (RENAPER, ANSES) y sometidos a controles de calidad para garantizar su precisión.
Las estimaciones poblacionales para la versión 2023 fueron calculadas multiplicando la cantidad de viviendas registradas en el RENABAP, por el promedio de personas por vivienda y el promedio de hogares por vivienda, según los datos del Censo Nacional de Población, Hogares y Viviendas (INDEC 2010) aplicados a cada barrio. Esta metodología reduce la precisión de los datos demográficos, especialmente en contextos de transformación urbana acelerada, dado que muchos barrios populares han experimentado cambios sustanciales desde 2010. Las implicancias críticas de estas limitaciones se analizan en profundidad en la sección correspondiente de este estudio.
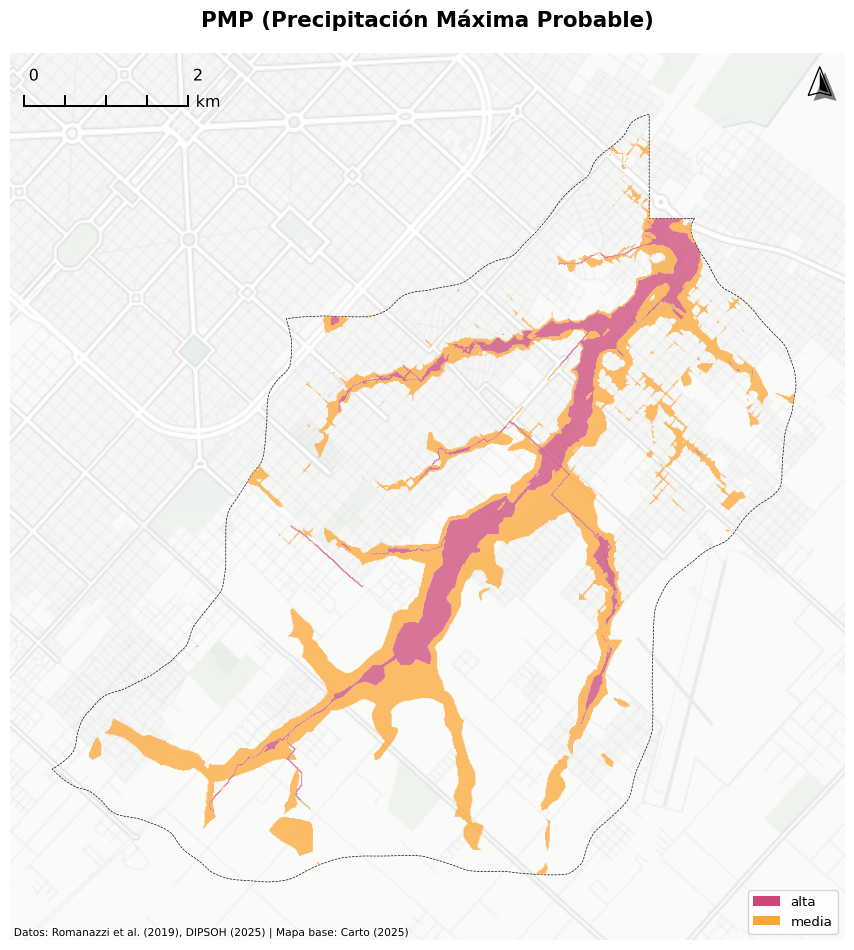
Los datos del peligro de inundación utilizados en este análisis fueron desarrollados por la Facultad de Ingeniería de la Universidad Nacional de La Plata, en el marco del Plan de Reducción del Riesgo por Inundaciones (PRRI) en la Región de La Plata (P. Romanazzi et al. 2019; P. G. Romanazzi, Mena, and Valinoti 2023). La información fue generada mediante la aplicación del modelo hidrológico-hidráulico bidimensional FLO-2D, que permitió simular la dinámica de inundación de todas las cuencas del partido de La Plata para distintos escenarios de eventos pluviométricos extremos.
Este modelo calcula las principales variables hidráulicas (altura del agua, velocidad y caudal) a lo largo del tiempo. A partir de estos resultados se elaboraron mapas de peligrosidad que combinan la profundidad con la velocidad de la corriente, ofreciendo un indicador más completo que los mapas tradicionales basados únicamente en máximas profundidades.
En el caso específico de la Cuenca del Arroyo Maldonado, el modelo digital de terreno (MDT) fue actualizado en 2024 como parte del proyecto de investigación Construyendo Resiliencia del Centro de Investigaciones Urbanas y Territoriales (Etulaín 2023). Esta actualización se realizó mediante un relevamiento topográfico detallado de todas las esquinas y calles de la cuenca, así como de diversas secciones del cauce del arroyo, con el objetivo de capturar con mayor precisión los patrones de drenaje y la topografía urbana de la ciudad (Carner, Ortiz, and Lacunza en edición).
El análisis a escala del Partido de La Plata se basa específicamente en los datos de peligrosidad generados para el escenario de la Precipitación Máxima Probable (PMP), utilizado en el PRRI. Para el caso de la Cuenca del Arroyo Maldonado, se realizó un análisis comparativo de la exposición al riesgo según períodos de retorno: 25 años, 100 años (Etulaín 2023) y la PMP del PRRI (P. Romanazzi et al. 2019).
4.3.3 Google-Microsoft-OSM Open Buildings
Los datos de Google-Microsoft-OSM Open Buildings(VIDA 2023) brindan una herramienta más precisa para identificar la ubicación de los asentamientos humanos. Este conjunto integra huellas edilicias provenientes de Google V3 Open Buildings, Microsoft GlobalMLFootprints, y OpenStreetMap building footprints, conteniendo más de 2.7 mil millones de edificaciones georreferenciadas.
Estos datos han sido utilizados en evaluaciones de riesgo de inundación por empresas globales de riesgo financiero, como ICE, demostrando su utilidad para mapear la exposición climática a nivel de huella individual. Su resolución espacial permite estimar con mayor detalle la distribución de las estructuras habitacionales en el área analizada.
Sin embargo, en ausencia de información sobre el uso específico de cada edificación (residencial, comercial, institucional), y sin datos sobre el número de unidades habitacionales ni de habitantes por edificio, las estimaciones poblacionales que podemos obtener de estas huellas son necesariamente aproximadas. Podemos inferir patrones de ocupación espacial, pero no acceder a una comprensión precisa sobre quién vive allí ni cuántas personas habitan cada estructura.
4.3.4 Límites municipales
Los límites municipales del Partido de La Plata fueron obtenidos del Instituto Geográfico Nacional (Instituto Geográfico Nacional 2025). Los datos representan la división político-administrativa de tercer orden que incluye comunas, juntas vecinales y demás formas de gobiernos.
# Calcular variables para el contextototal_barrios =int(len(renabap_pba_intersect))total_familias =int(renabap_pba_intersect["familias_aproximadas"].sum())area_barrios_ha =int(renabap_total_area_ha)porcentaje_cobertura =float(round(percentage_coverage, 1))# Calcular barrios que intersectan con zonas de peligrobarrios_with_peligro = gpd.sjoin( renabap_pba_intersect, peligro_la_plata, how="inner", predicate="intersects")# Contar barrios por nivel de peligrobarrios_peligro_alta =int(len( barrios_with_peligro[barrios_with_peligro["PELIGROSID"] =="alta"]["id_renabap" ].unique() ))barrios_peligro_media =int(len( barrios_with_peligro[barrios_with_peligro["PELIGROSID"] =="media"]["id_renabap" ].unique() ))# Contar barrios por tipo de peligro (sin duplicados)barrios_peligro_summary = ( barrios_with_peligro.groupby("id_renabap")["PELIGROSID"] .agg(["nunique", "unique"]) .reset_index())barrios_peligro_summary["tiene_alta"] = barrios_peligro_summary["unique"].apply(lambda x: "alta"in x)barrios_peligro_summary["tiene_media"] = barrios_peligro_summary["unique"].apply(lambda x: "media"in x)# Contar barrios por categoríabarrios_solo_alta =int( ( barrios_peligro_summary["tiene_alta"] &~barrios_peligro_summary["tiene_media"] ).sum())barrios_solo_media =int( ( barrios_peligro_summary["tiene_media"] &~barrios_peligro_summary["tiene_alta"] ).sum())barrios_ambos_peligros =int( ( barrios_peligro_summary["tiene_alta"] & barrios_peligro_summary["tiene_media"] ).sum())# Total de barrios que intersectan con cualquier nivel de peligro (sin duplicados)barrios_total_peligro =int(len(barrios_with_peligro["id_renabap"].unique()))# Obtener total de edificios en La Platatotal_buildings_la_plata =len(buildings_proj)# Obtener todas las edificios que intersectan con los barrios (corregir warning de deprecación)buildings_in_barrios = buildings_proj[ buildings_proj.geometry.intersects(renabap_pba_intersect.union_all())]total_buildings_in_barrios =len(buildings_in_barrios)viviendas_faltantes = ( total_buildings_in_barrios -30753) # 30753 es el número oficial de RENABAP# Calcular porcentaje de edificios en barriosbuildings_percentage =float(round((total_buildings_in_barrios / total_buildings_la_plata) *100, 1))# Calcular área total de barrios populares en hectáreasbarrios_total_area_ha =float(round(renabap_pba_intersect.geometry.area.sum() /10000, 1))# Calcular el área real de superposición entre barrios populares y zonas de peligro# Primero, crear uniones de las zonas de peligro por tipopeligro_alta_union = peligro_la_plata[peligro_la_plata["PELIGROSID"] =="alta"].union_all()peligro_media_union = peligro_la_plata[peligro_la_plata["PELIGROSID"] =="media"].union_all()# Calcular el área de superposición real entre barrios y zonas de peligro altobarrios_intersect_alta = renabap_pba_intersect.copy()barrios_intersect_alta["geometry"] = renabap_pba_intersect.geometry.intersection(peligro_alta_union)barrios_intersect_alta = barrios_intersect_alta[~barrios_intersect_alta.geometry.is_empty]barrios_area_peligro_alta_ha =float(round(barrios_intersect_alta.geometry.area.sum() /10000, 1))barrios_pct_peligro_alta =float(round((barrios_area_peligro_alta_ha / barrios_total_area_ha) *100, 1))# Calcular el área de superposición real entre barrios y zonas de peligro mediobarrios_intersect_media = renabap_pba_intersect.copy()barrios_intersect_media["geometry"] = renabap_pba_intersect.geometry.intersection(peligro_media_union)barrios_intersect_media = barrios_intersect_media[~barrios_intersect_media.geometry.is_empty]barrios_area_peligro_media_ha =float(round(barrios_intersect_media.geometry.area.sum() /10000, 1))barrios_pct_peligro_media =float(round((barrios_area_peligro_media_ha / barrios_total_area_ha) *100, 1))# Calcular el área total de barrios populares como porcentaje del partidobarrios_pct_del_partido =float(round((barrios_total_area_ha / la_plata_area_ha) *100, 1))# Calcular área para cada tipo de peligro en hectáreaspeligro_areas = ( peligro_la_plata.groupby("PELIGROSID")["geometry"] .apply(lambda x: x.area.sum() /10000# Convertir m² a hectáreas ) .reset_index())peligro_areas.columns = ["tipo_peligro", "area_ha"]# Calcular porcentajespeligro_areas["porcentaje"] = (peligro_areas["area_ha"] / la_plata_area_ha) *100# Variables para cada nivel de peligro (convertir a float Python nativo)peligro_alta_ha =float(round(peligro_areas[peligro_areas["tipo_peligro"] =="alta"]["area_ha"].iloc[0], 1))peligro_alta_pct =float(round( peligro_areas[peligro_areas["tipo_peligro"] =="alta"]["porcentaje"].iloc[0], 1 ))peligro_media_ha =float(round(peligro_areas[peligro_areas["tipo_peligro"] =="media"]["area_ha"].iloc[0], 1))peligro_media_pct =float(round( peligro_areas[peligro_areas["tipo_peligro"] =="media"]["porcentaje"].iloc[0], 1 ))# Área total cubierta por zonas de peligro (convertir a float Python nativo)area_total_peligro_ha =float(round(peligro_areas["area_ha"].sum(), 1))porcentaje_total_peligro =float(round(peligro_areas["porcentaje"].sum(), 1))
Según los datos oficiales de RENABAP, hay un total de 33.888 familias y 30.753 viviendas en 166 barrios populares en el Partido de La Plata. Sin embargo, estos datos fueron creados basándose en proyecciones del Censo Argentino de 2010 hacia 2023. Nuestro análisis de datos de huellas de edificaciones encuentra un total de 72.328 techos en barrios populares en La Plata, representando aproximadamente 41.575 edificaciones adicionales que no están contabilizadas en los datos oficiales.
Los barrios populares ocupan un total de 1.760,9 hectáreas, representando el 2,0% del territorio total del Partido de La Plata (89.667,9 hectáreas). El Partido de La Plata incluye 4.202,3 hectáreas en peligro de inundación alto (4,7% del partido) y 19.515,0 hectáreas en peligro de inundación medio (21,8% del partido) bajo el escenario de PMP.
Respecto a la exposición de los barrios populares al peligro de inundación, se identificó que 124 barrios (74,7% del total) están localizados en zonas con peligro alto o medio de inundación. Específicamente, 1 barrio está únicamente en zona de peligro alto, 46 barrios están únicamente localizados en zona de peligro medio, y 77 barrios presentan tanto peligro alto como medio dentro de sus límites. En términos de área de superposición 153,5 hectáreas (8,7% del área total de barrios populares) se superponen con zonas de peligro alto, mientras que 310,1 hectáreas (17,6% del área total de barrios populares) se superponen con zonas de peligro medio.
Mostrar código
fig1, ax1 = create_consistent_map("Asentamientos RENABAP en La Plata", crs=USE_CRS, boundary_gdf=la_plata, bounds=common_bounds, attribution="Datos: RENABAP (2023), IGN (2025) | Mapa base: Carto (2025)", scalebar_length=0.20)renabap_pba_intersect_3857 = renabap_pba_intersect.to_crs(WEB_MERCATOR_CRS)renabap_pba_intersect_3857.plot( ax=ax1, facecolor="none", edgecolor="black", linewidth=0.5, legend=False, zorder=10)plt.tight_layout()plt.show()# Reorder the categories so they map correctly to plasma colormappeligro_clipped_3857["PELIGROSID_ordered"] = pd.Categorical( peligro_clipped_3857["PELIGROSID"], categories=["media", "alta"], ordered=True,)fig2, ax2 = create_consistent_map("Zonas de Peligro en La Plata", crs=USE_CRS, boundary_gdf=la_plata, bounds=common_bounds, attribution="Datos: Romanazzi et al. (2019), IGN (2025) | Mapa base: Carto (2025)", scalebar_length=0.20)color_map = peligro_clipped_3857["PELIGROSID"].map(PELIGROSIDAD_COLORS)peligro_clipped_3857.plot( ax=ax2, color=color_map, alpha=0.75, zorder=5,)ax2.legend(handles=PELIGROSIDAD_LEGEND, loc="lower right")plt.tight_layout()plt.show()fig3, ax3 = create_consistent_map("Huellas de edificios", crs=USE_CRS, boundary_gdf=la_plata, bounds=common_bounds, attribution="Datos: VIDA (2023), IGN (2025) | Mapa base: Carto (2025)", scalebar_length=0.20)buildings_3857 = buildings_proj.to_crs(WEB_MERCATOR_CRS)buildings_3857.plot(ax=ax3, facecolor="grey", edgecolor="none", alpha=0.7)plt.tight_layout()plt.show()
(a) Asentamientos RENABAP en La Plata
(b) Zonas de Peligro en La Plata
(c) Huellas de edificios
Figure 4.1: Fuentes de datos para análisis de exposición
4.5 Metodología
En versiones anteriores de este análisis, el trabajo se realizó mediante una interpolación areal simple del porcentaje de superposición de cada área de peligro de inundación con los barrios populares. Este enfoque presenta dos problemas fundamentales que este estudio busca abordar.
El primer problema es que la interpolación areal es inherentemente imprecisa, ya que asume lo que se conoce como el problema de la unidad areal modificable y presupone que la población se distribuye uniformemente en el espacio. Estudios confirman que cuando se asume distribución uniforme de población en áreas extensas (como datos de censo a nivel de sección), las estimaciones de exposición a inundaciones son inexactas, requiriendo datos de mayor resolución que no asuman distribución uniforme (Smith et al. 2019). La población, de hecho, no se distribuye uniformemente en el espacio; frecuentemente las edificaciones se agrupan ya sea alejándose de las zonas de peligro de inundación o concentrándose en zonas de alto peligro de inundación. Por tanto, es fundamental comprender con estimaciones más precisas dónde vive realmente la gente.
El segundo problema radica en que los propios datos del RENABAP, según nuestro análisis aquí presentado, parecen contar de forma incorrecta tanto el dato de familias como de viviendas pertenecientes a un barrio, dado que se ha comprobado la existencia de muchas más edificaciones que las viviendas que indican los datos oficiales, en un total de 41.575 techos o edificaciones de más.
Este hallazgo ha sido posible debido a la existencia de las huellas de edificaciones globales derivadas de satélite que han surgido en los últimos años de Google-Microsoft-OSM, entre otros. Uno de los objetivos principales de este análisis es demostrar que estos datos pueden utilizarse para estimar la exposición de manera más precisa, tanto en términos metodológicos como en la mejora sobre conjuntos de datos nacionales existentes, en este caso del RENABAP.
Por tanto, en este estudio utilizamos el número de edificaciones que se localizan en diferentes zonas de peligro de inundación, diferenciando entre alta y media y utilizando específicamente los datos de peligrosidad generados para el escenario de PMP. Aunque los datos del RENABAP estiman aproximadamente 1,1 familias por vivienda, medimos la exposición en términos del número comparativo de techos o edificaciones, lo cual es suficiente para demostrar las limitaciones del RENABAP y proporcionar estimaciones razonablemente más ajustadas a la realidad en cuanto a la exposición de la población vulnerable frente a inundaciones.
Basándonos en conversaciones con funcionarios municipales y académicos, asumimos que la mayoría de las edificaciones en barrios populares son residenciales de uno a dos pisos, creando una correspondencia estrecha entre número de edificaciones y familias. Esta suposición es válida para este contexto específico, aunque no aplicaría para áreas urbanas con edificios en altura.
Mostrar código
# Definir orden de prioridad de peligro y simplificarhazard_priority = {"alta": 2, "media": 1}peligro_simple = peligro_la_plata.dissolve(by="PELIGROSID").reset_index()# Construir índices espaciales para operaciones más rápidasbuildings_proj.sindexrenabap_pba_intersect.sindexpeligro_simple.sindex# Filtrar edificios a solo aquellos que podrían intersectar con barrios# usando intersección de cajas delimitadoras primero (mucho más rápido que intersección geométrica)# Crear una unión de todas las cajas delimitadoras individuales de barrios# Obtener cajas delimitadoras individuales para cada barriobarrio_boxes = []for _, barrio in renabap_pba_intersect.iterrows(): bounds = barrio.geometry.bounds barrio_boxes.append(box(bounds[0], bounds[1], bounds[2], bounds[3]))# Crear una unión de todas las cajas delimitadoras de barriosbarrios_union = unary_union(barrio_boxes)# Filtrar edificios a solo aquellos que intersectan con cualquier caja delimitadora de barriobuildings_candidates = buildings_proj[buildings_proj.geometry.intersects(barrios_union)]# Ahora hacer el join espacial en el dataset filtrado mucho más pequeñobuildings_with_barrios = gpd.sjoin( buildings_candidates, renabap_pba_intersect[ ["id_renabap", "nombre_barrio", "familias_aproximadas", "geometry"] ], how="inner", predicate="within",)buildings_with_barrios = buildings_with_barrios.drop(columns=["index_right"]).copy()# Etapa 1: Obtener edificios que están claramente dentro de zonas de peligro (rápido)buildings_within_hazards = gpd.sjoin( buildings_with_barrios, peligro_simple[["PELIGROSID", "geometry"]], how="inner", predicate="within",)# Etapa 2: Encontrar edificios que están cerca de los límites de peligro pero no dentro# Usar un pequeño buffer alrededor de las zonas de peligro para encontrar casos límite potencialeshazard_buffered = peligro_simple.copy()hazard_buffered["geometry"] = peligro_simple.geometry.buffer(5) # buffer de 5 metrosbuildings_near_hazards = gpd.sjoin( buildings_with_barrios, hazard_buffered[["PELIGROSID", "geometry"]], how="inner", predicate="within",)# Encontrar casos límite (cerca de peligros pero no dentro de los peligros originales)within_ids =set(buildings_within_hazards.index)near_ids =set(buildings_near_hazards.index)edge_case_ids = near_ids - within_idsbuildings_edge_cases = buildings_with_barrios.loc[list(edge_case_ids)]# Etapa 3: Usar intersects solo en los casos límitebuildings_edge_cases_with_hazard = gpd.sjoin( buildings_edge_cases, peligro_simple[["PELIGROSID", "geometry"]], how="left", predicate="intersects",)# Combinar resultadosbuildings_with_peligro_barrio = pd.concat( [buildings_within_hazards, buildings_edge_cases_with_hazard], ignore_index=True)# Resolver duplicados y contarbuildings_barrio_final = buildings_with_peligro_barrio.dropna( subset=["PELIGROSID"]).copy()buildings_barrio_final.loc[:, "prioridad"] = buildings_barrio_final["PELIGROSID"].map( hazard_priority)buildings_barrio_unique = buildings_barrio_final.sort_values("prioridad", ascending=False).drop_duplicates(subset=buildings_barrio_final.geometry.name, keep="first")# Calcular exposición por barrioedificios_por_barrio_peligro = ( buildings_barrio_unique.groupby(["id_renabap", "PELIGROSID"]) .size() .reset_index(name="edificios_expuestos"))total_edificios_barrio = ( buildings_with_barrios.groupby("id_renabap") .size() .reset_index(name="total_edificios"))exposure_barrio = edificios_por_barrio_peligro.merge( total_edificios_barrio, on="id_renabap")exposure_barrio["proporcion"] = ( exposure_barrio["edificios_expuestos"] / exposure_barrio["total_edificios"])familias_barrio = renabap_pba_intersect[ ["id_renabap", "nombre_barrio", "familias_aproximadas"]].drop_duplicates()final_exposure_barrio = exposure_barrio.merge(familias_barrio, on="id_renabap")final_exposure_barrio["fam_expuestas"] = ( final_exposure_barrio["proporcion"] * final_exposure_barrio["familias_aproximadas"])resultado_exposicion_barrio = final_exposure_barrio[ ["id_renabap","nombre_barrio","PELIGROSID","edificios_expuestos", ]].rename(columns={"PELIGROSID": "peligrosidad"})# === ANÁLISIS POR CUENCA ===# Usar edificios ya en barrios para análisis de cuencabuildings_in_settlements = buildings_with_barrios.copy()# Spatial joins para cuencabuildings_with_cuenca = gpd.sjoin( buildings_in_settlements, cuencas[["Cuenca", "eje", "geometry"]], how="left", predicate="within",)buildings_with_cuenca = buildings_with_cuenca.drop(columns=["index_right"]).copy()buildings_with_peligro_cuenca = gpd.sjoin( buildings_in_settlements, peligro_simple[["PELIGROSID", "geometry"]], how="left", predicate="within",)# Combinar y filtrarbuildings_cuenca_final = buildings_in_settlements.copy()buildings_cuenca_final.loc[:, "Cuenca"] = buildings_with_cuenca["Cuenca"]buildings_cuenca_final.loc[:, "eje"] = buildings_with_cuenca["eje"]buildings_cuenca_final.loc[:, "PELIGROSID"] = buildings_with_peligro_cuenca["PELIGROSID"]buildings_cuenca_final = buildings_cuenca_final.dropna( subset=["Cuenca", "PELIGROSID"]).copy()# Resolver duplicados y calcular exposición por cuencabuildings_cuenca_final.loc[:, "prioridad"] = buildings_cuenca_final["PELIGROSID"].map( hazard_priority)buildings_cuenca_unique = buildings_cuenca_final.sort_values("prioridad", ascending=False).drop_duplicates(subset=buildings_cuenca_final.geometry.name, keep="first")edificios_por_cuenca_peligro = ( buildings_cuenca_unique.groupby(["Cuenca", "PELIGROSID"]) .size() .reset_index(name="edificios_expuestos"))total_edificios_cuenca = ( buildings_with_cuenca.dropna(subset=["Cuenca"]) .groupby("Cuenca") .size() .reset_index(name="total_edificios"))exposure_cuenca = edificios_por_cuenca_peligro.merge( total_edificios_cuenca, on="Cuenca")exposure_cuenca["proporcion"] = ( exposure_cuenca["edificios_expuestos"] / exposure_cuenca["total_edificios"])familias_cuenca = ( settle_hazard_cuencas.drop_duplicates("id_renabap") .groupby("Cuenca")["familias_aproximadas"] .sum() .reset_index())final_exposure_cuenca = exposure_cuenca.merge(familias_cuenca, on="Cuenca")final_exposure_cuenca["fam_expuestas"] = ( final_exposure_cuenca["proporcion"] * final_exposure_cuenca["familias_aproximadas"])resultado_exposicion_cuenca = final_exposure_cuenca[ ["Cuenca", "PELIGROSID", "edificios_expuestos"]].rename(columns={"PELIGROSID": "peligrosidad"})# === ANÁLISIS POR EJE ===# Usar los edificios ya procesados con cuenca y peligrobuildings_eje_final = buildings_cuenca_final.dropna(subset=["eje"]).copy()# Resolver duplicados por prioridad de peligrobuildings_eje_final.loc[:, "prioridad"] = buildings_eje_final["PELIGROSID"].map( hazard_priority)buildings_eje_unique = buildings_eje_final.sort_values("prioridad", ascending=False).drop_duplicates(subset=buildings_eje_final.geometry.name, keep="first")# Calcular exposición por eje y peligrosidadedificios_por_eje_peligro = ( buildings_eje_unique.groupby(["eje", "PELIGROSID"]) .size() .reset_index(name="edificios_expuestos"))total_edificios_eje = ( buildings_with_cuenca.dropna(subset=["eje"]) .groupby("eje") .size() .reset_index(name="total_edificios"))exposure_eje = edificios_por_eje_peligro.merge(total_edificios_eje, on="eje")exposure_eje["proporcion"] = ( exposure_eje["edificios_expuestos"] / exposure_eje["total_edificios"])familias_por_eje = ( settle_hazard_cuencas.drop_duplicates("id_renabap") .groupby("eje")["familias_aproximadas"] .sum() .reset_index())final_exposure_eje = exposure_eje.merge(familias_por_eje, on="eje")final_exposure_eje["fam_expuestas"] = ( final_exposure_eje["proporcion"] * final_exposure_eje["familias_aproximadas"])resultado_exposicion_eje = final_exposure_eje[ ["eje", "PELIGROSID", "edificios_expuestos"]].rename(columns={"PELIGROSID": "peligrosidad"})
4.5.1 Limitaciones de los datos del RENABAP
Los datos del RENABAP presentan limitaciones importantes que justifican el uso de huellas de edificaciones como alternativa más precisa. Los datos más recientes del RENABAP de 2023 subestiman significativamente el número total de familias por barrio popular. Estos datos -como se ha mencionado- se basan en proyecciones derivadas del censo de 2010, lo que ha resultado en estimaciones considerablemente desactualizadas.
Mostrar código
# =============================================================================# ANALYTICAL PROCESSING: RENABAP DATA VALIDATION# =============================================================================# Calcular familias estimadas basadas en edificios (1,1 familias por edificio)ratio_fam_edif = ( buildings_with_barrios.groupby(["id_renabap", "familias_aproximadas"]) .size() .reset_index(name="total_edificios"))ratio_fam_edif["familias_estimadas_edificios"] = ratio_fam_edif["total_edificios"] *1.1# Calcular el error porcentual: (RENABAP - Edificios) / Edificios * 100ratio_fam_edif["error_porcentual"] = ( ( ratio_fam_edif["familias_aproximadas"]- ratio_fam_edif["familias_estimadas_edificios"] )/ ratio_fam_edif["familias_estimadas_edificios"]) *100# =============================================================================# GRAPHICS: RENABAP ERROR ANALYSIS# =============================================================================# Crear histogramaplt.figure(figsize=(12, 6))plt.hist( ratio_fam_edif["error_porcentual"], bins=30, edgecolor="none", color=PELIGROSIDAD_COLORS["media"],)# Personalizar el gráficoplt.title("Error de Estimación de RENABAP vs Estimación por Edificios", fontsize=16, fontweight="bold",)plt.xlabel("Error Porcentual (%)", fontsize=12)plt.ylabel("Frecuencia (Número de Barrios)", fontsize=12)# Agregar líneas de referenciamean_error = ratio_fam_edif["error_porcentual"].mean()median_error = ratio_fam_edif["error_porcentual"].median()# Rango de personas no contabilizadas (3-5 personas por vivienda)personas_min_faltantes =round(viviendas_faltantes *3, -3) # Round to nearest thousandpersonas_max_faltantes =round(viviendas_faltantes *5, -3) # Round to nearest thousandplt.axvline( mean_error, color="black", linestyle="--", linewidth=2, label=f"Error promedio: {mean_error:.1f}%",)plt.axvline( median_error, color="black", linestyle="dotted", linewidth=2, label=f"Error mediano: {median_error:.1f}%",)plt.legend()plt.tight_layout()plt.show()
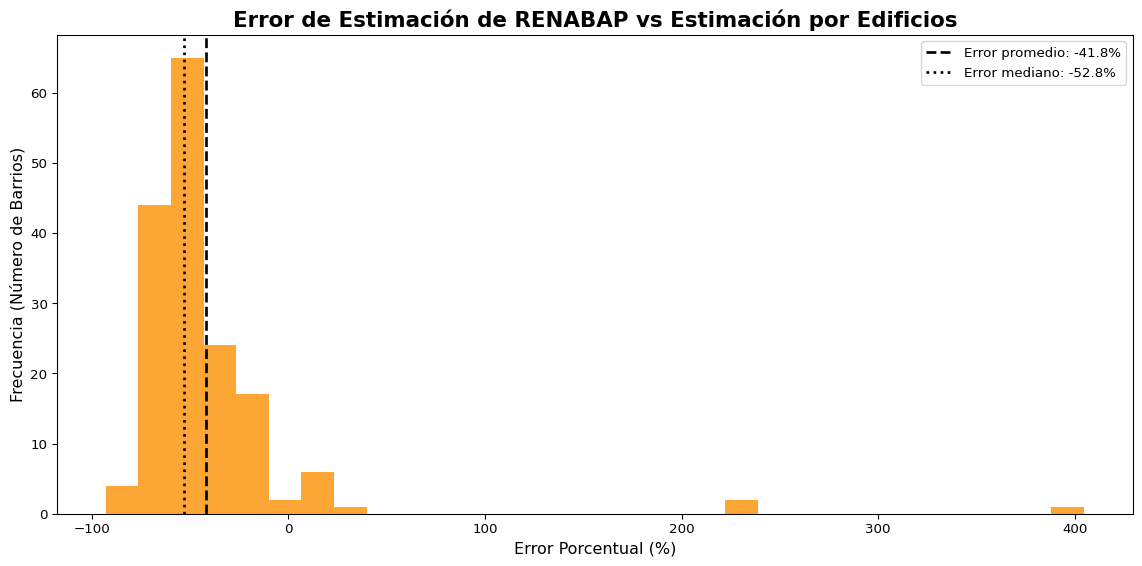
Figure 4.2: Distribución del error porcentual en las estimaciones del RENABAP comparado con estimaciones basadas en edificios
Nuestro análisis comparativo entre los datos del RENABAP y el conteo de huellas de edificaciones o techos, revela que el RENABAP subestima el número de estructuras habitacionales en un promedio del 41%. A nivel agregado, esto se traduce en aproximadamente 41.575 viviendas faltantes que no están contabilizadas en las estadísticas oficiales del RENABAP. Si usamos la estimación del RENABAP de aproximadamente 1,1 familias por edificio, podemos considerar aproximadamente 45.732 familias. Tomando un rango razonable de 3 a 5 personas por familia, esta subestimación representa entre 137.000 y 229.000 personas que podrían estar no contabilizadas en los barrios populares. Esta discrepancia demuestra las limitaciones de los datos del RENABAP para la evaluación de la exposición a riesgos de inundación y la planificación de políticas públicas.
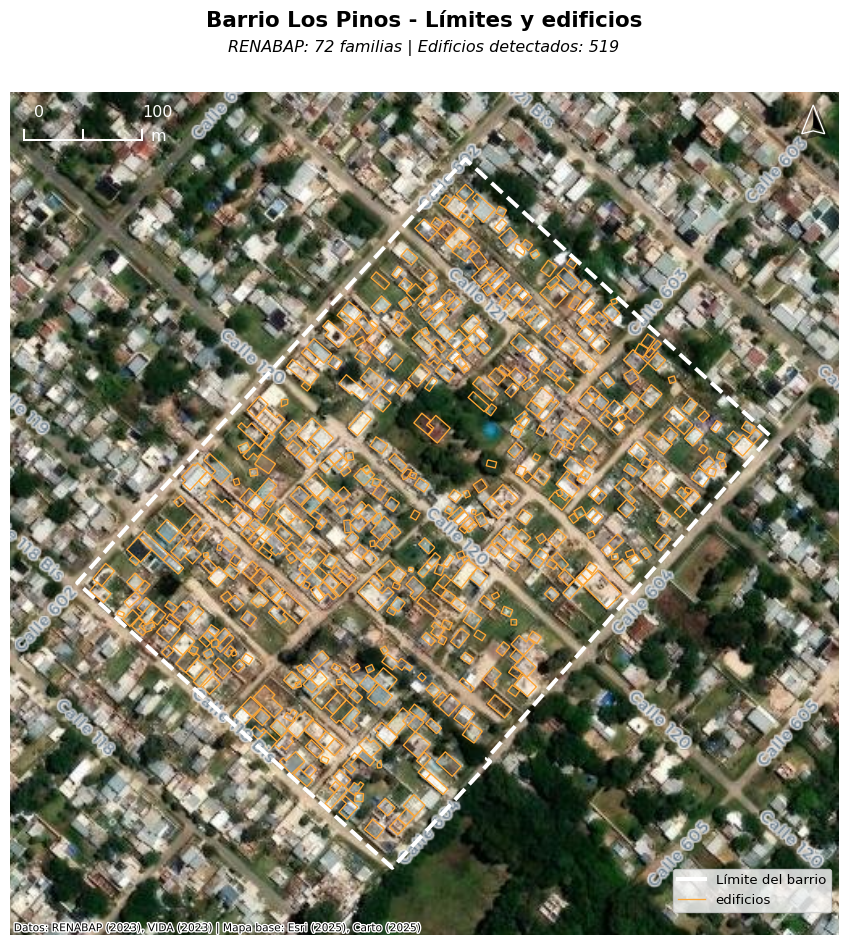
También podemos examinar imágenes satelitales de un barrio popular a modo de ejemplo, donde se analiza las huellas de las edificaciones superpuestas para tener una idea de la veracidad de los datos. En el barrio Los Pinos, las estimaciones del RENABAP dice que tiene solo 72 familias. Nuestros datos cuentan 519 edificaciones o techos, lo que debe corresponder a aproximadamente 570 familias (1,1 familia por edificación), que es casi ocho veces más que los datos que contabiliza el RENABAP.
Al examinar otros ejemplos de barrios entre las huellas de edificaciones detectadas y los datos oficiales del RENABAP, observamos que frecuentemente encontramos órdenes de magnitud de más edificaciones o techos que familias estimadas, representando miles de familias no contabilizadas.
Mostrar código
# Filtrar para obtener solo el barrio con id_renabap 5688barrio_5688 = renabap_pba_intersect[renabap_pba_intersect["id_renabap"] ==5688].copy()iflen(barrio_5688) ==0:print("No se encontró el barrio con id_renabap 5688")else:# Obtener edificios en este barrio buildings_5688 = buildings_with_barrios[ buildings_with_barrios["id_renabap"] ==5688 ].copy()# Convertir a Web Mercator barrio_5688_3857 = barrio_5688.to_crs(WEB_MERCATOR_CRS) buildings_5688_3857 = buildings_5688.to_crs(WEB_MERCATOR_CRS)# Crear el mapa fig, ax = plt.subplots(figsize=DEFAULT_FIGSIZE)# Configurar límites basados en el barrio bounds = barrio_5688_3857.total_bounds margin =50# metros ax.set_xlim(bounds[0] - margin, bounds[2] + margin) ax.set_ylim(bounds[1] - margin, bounds[3] + margin)# Agregar basemap de contextily cx.add_basemap(ax, crs=WEB_MERCATOR_CRS, source=cx.providers.Esri.WorldImagery, attribution="Datos: RENABAP (2023), VIDA (2023) | Mapa base: Esri (2025), Carto (2025)")# Plot de edificios con contorno naranja (sin fill) buildings_5688_3857.plot( ax=ax, facecolor="none", edgecolor=PELIGROSIDAD_COLORS["media"], linewidth=1 )# Plot del límite del barrio con estilo consistente barrio_5688_3857.plot( ax=ax, facecolor="none", edgecolor="white", # White for satellite imagery visibility linewidth=3, linestyle="--", zorder=10, ) cx.add_basemap(ax, crs=WEB_MERCATOR_CRS, source=cx.providers.CartoDB.PositronOnlyLabels, attribution="") scale_bar( ax=ax, location="upper left", style="ticks", bar={"projection": "axis","minor_type": "none","tickcolors": "white","basecolors": "white","max": 100, }, labels={"style": "first_last", "textcolors": ["white"], "stroke_width": 0}, units={"label": "m", "textcolor": "white", "stroke_width": 0}, ) north_arrow( ax, location="upper right", scale=0.3, # Small size rotation={"degrees": 0}, base={"facecolor": "none", "edgecolor": "white", "linewidth": 1}, fancy=True, shadow=True, label=False, # Hide the "N" text )# Limpiar el mapa barrio_nombre = barrio_5688["nombre_barrio"].iloc[0] familias_renabap =int(barrio_5688["familias_aproximadas"].iloc[0]) total_edificios =len(buildings_5688)# Título principal usando suptitle fig.suptitle(f"Barrio {barrio_nombre} - Límites y edificios", fontsize=16, fontweight="bold", y=0.98, )# Subtítulo usando title ax.set_title(f"RENABAP: {familias_renabap} familias | Edificios detectados: {total_edificios}", fontsize=12, style="italic", pad=30, ) ax.set_xticks([]) ax.set_yticks([]) ax.set_xlabel("") ax.set_ylabel("") ax.spines["top"].set_visible(False) ax.spines["right"].set_visible(False) ax.spines["bottom"].set_visible(False) ax.spines["left"].set_visible(False)# Agregar leyenda simple legend_elements = [ plt.Line2D([0], [0], color="white", linewidth=3, label="Límite del barrio"), plt.Line2D( [0], [0], color=PELIGROSIDAD_COLORS["media"], linewidth=1, label="edificios", ), ] ax.legend(handles=legend_elements, loc="lower right", bbox_to_anchor=(1.0, 0.02)) plt.tight_layout() plt.show()
Figure 4.3: Ejemplo de discrepancia en los datos del RENABAP: el barrio Los Pinos con límites oficiales y edificios detectadas
Al examinar otros ejemplos de barrios con las mayores discrepancias entre las huellas de edificios detectadas y los datos oficiales del RENABAP, observamos que frecuentemente encontramos órdenes de magnitud más edificios que familias estimadas, representando miles de familias no contabilizadas.
Mostrar código
# IDs de los barrios a visualizarbarrio_ids = [4577, 65, 6541, 17]for i, barrio_id inenumerate(barrio_ids):# Filtrar para obtener el barrio específico barrio_data = renabap_pba_intersect[ renabap_pba_intersect["id_renabap"] == barrio_id ].copy()iflen(barrio_data) ==0:print(f"No se encontró el barrio con id_renabap {barrio_id}")continue# Obtener edificios en este barrio buildings_data = buildings_with_barrios[ buildings_with_barrios["id_renabap"] == barrio_id ].copy()# Convertir a Web Mercator barrio_3857 = barrio_data.to_crs(WEB_MERCATOR_CRS) buildings_3857 = buildings_data.to_crs(WEB_MERCATOR_CRS)# Crear el mapa individual fig, ax = plt.subplots(figsize=DEFAULT_FIGSIZE)# Configurar límites basados en el barrio bounds = barrio_3857.total_bounds margin =50# metros ax.set_xlim(bounds[0] - margin, bounds[2] + margin) ax.set_ylim(bounds[1] - margin, bounds[3] + margin)# Agregar basemap de contextily cx.add_basemap( ax, crs=WEB_MERCATOR_CRS, source=cx.providers.Esri.WorldImagery, attribution="Datos: RENABAP (2023), VIDA (2023) | Mapa base: Esri (2025)" )# Plot de edificios con contorno naranja (sin fill) buildings_3857.plot( ax=ax, facecolor="none", edgecolor=PELIGROSIDAD_COLORS["media"], linewidth=1 )# Plot del límite del barrio con estilo consistente barrio_3857.plot( ax=ax, facecolor="none", edgecolor="white", linewidth=3, linestyle="--", zorder=10, ) cx.add_basemap(ax, crs=WEB_MERCATOR_CRS, source=cx.providers.CartoDB.PositronOnlyLabels, attribution="") scale_bar( ax=ax, location="upper left", style="ticks", bar={"projection": "axis","minor_type": "none","tickcolors": "white","basecolors": "white","max": 200, }, labels={"style": "first_last", "textcolors": ["white"], "stroke_width": 0}, units={"label": "m", "textcolor": "white", "stroke_width": 0}, )# Agregar flecha del norte north_arrow( ax, location="upper right", scale=0.3, rotation={"degrees": 0}, base={"facecolor": "none", "edgecolor": "white", "linewidth": 1}, fancy=True, shadow=True, label=False, )# Obtener información del barrio barrio_nombre = barrio_data["nombre_barrio"].iloc[0] familias_renabap =int(barrio_data["familias_aproximadas"].iloc[0]) total_edificios =len(buildings_data)# Título principal usando suptitle fig.suptitle(f"Barrio {barrio_nombre}", fontsize=16, fontweight="bold", y=0.98)# Subtítulo usando title ax.set_title(f"RENABAP: {familias_renabap} familias | Edificios detectados: {total_edificios}", fontsize=12, style="italic", pad=30, )# Limpiar el mapa ax.set_xticks([]) ax.set_yticks([]) ax.set_xlabel("") ax.set_ylabel("") ax.spines["top"].set_visible(False) ax.spines["right"].set_visible(False) ax.spines["bottom"].set_visible(False) ax.spines["left"].set_visible(False) plt.tight_layout() plt.show()
(a)
(b)
(c)
(d)
Figure 4.4
4.6 Procesamiento y resultados
Mostrar código
# =============================================================================# EXPOSICIÓN POR BARRIO# =============================================================================# Preparar datos - solo alta y mediaexposure_data = resultado_exposicion_barrio[ resultado_exposicion_barrio["peligrosidad"].isin(["alta", "media"])].copy()# Merge con geometrías para obtener centroidesexposure_gdf = exposure_data.merge( renabap_pba_intersect[["id_renabap", "geometry"]], on="id_renabap")exposure_gdf = gpd.GeoDataFrame(exposure_gdf, geometry="geometry", crs=USE_CRS)# Convertir a Web Mercator para el plottingexposure_gdf_3857 = exposure_gdf.to_crs(WEB_MERCATOR_CRS)la_plata_3857 = la_plata.to_crs(WEB_MERCATOR_CRS)# Filtrar exposición alta y media por nombre de barrio (excluyendo "Sin Nombre")barrios_alta_data = ( resultado_exposicion_barrio[ (resultado_exposicion_barrio["peligrosidad"] =="alta")& (resultado_exposicion_barrio["nombre_barrio"] !="Sin Nombre") ] .groupby("nombre_barrio")["edificios_expuestos"] .sum() .reset_index() .sort_values("edificios_expuestos", ascending=False) .head(10))barrios_media_data = ( resultado_exposicion_barrio[ (resultado_exposicion_barrio["peligrosidad"] =="media")& (resultado_exposicion_barrio["nombre_barrio"] !="Sin Nombre") ] .groupby("nombre_barrio")["edificios_expuestos"] .sum() .reset_index())# Merge para tener ambos nivelesbarrios_combined = barrios_alta_data.merge( barrios_media_data, on="nombre_barrio", how="left", suffixes=("_alta", "_media"))barrios_combined["edificios_expuestos_media"] = barrios_combined["edificios_expuestos_media"].fillna(0)# =============================================================================# EXPOSICIÓN POR CUENCA Y EJE# =============================================================================cuenca_alta_data = ( resultado_exposicion_cuenca[resultado_exposicion_cuenca["peligrosidad"] =="alta"] .groupby("Cuenca")["edificios_expuestos"] .sum() .reset_index() .sort_values("edificios_expuestos", ascending=False))cuenca_media_data = ( resultado_exposicion_cuenca[resultado_exposicion_cuenca["peligrosidad"] =="media"] .groupby("Cuenca")["edificios_expuestos"] .sum() .reset_index())# Merge para tener ambos nivelescuenca_combined = cuenca_alta_data.merge( cuenca_media_data, on="Cuenca", how="left", suffixes=("_alta", "_media"))cuenca_combined["edificios_expuestos_media"] = cuenca_combined["edificios_expuestos_media"].fillna(0)# === GRÁFICO DE EJES ===# Filtrar exposición alta y media por ejeeje_alta_data = ( resultado_exposicion_eje[resultado_exposicion_eje["peligrosidad"] =="alta"] .groupby("eje")["edificios_expuestos"] .sum() .reset_index() .sort_values("edificios_expuestos", ascending=False))eje_media_data = ( resultado_exposicion_eje[resultado_exposicion_eje["peligrosidad"] =="media"] .groupby("eje")["edificios_expuestos"] .sum() .reset_index())# Merge para tener ambos niveleseje_combined = eje_alta_data.merge( eje_media_data, on="eje", how="left", suffixes=("_alta", "_media"))eje_combined["edificios_expuestos_media"] = eje_combined["edificios_expuestos_media"].fillna(0)# =============================================================================# CALCULAR ESTADÍSTICAS RESUMEN PARA EL TEXTO# =============================================================================# Totales de edificios expuestos (sin duplicados)# Los edificios que intersectan con ambos peligros ya están resueltos por prioridad en buildings_barrio_uniquetotal_buildings_high_hazard =int(buildings_barrio_unique[buildings_barrio_unique["PELIGROSID"] =="alta"].shape[0])total_buildings_medium_hazard =int(buildings_barrio_unique[buildings_barrio_unique["PELIGROSID"] =="media"].shape[0])total_buildings_exposed = total_buildings_high_hazard + total_buildings_medium_hazard# Total de edificios en barriostotal_buildings_in_barrios =len(buildings_in_barrios)percentage_exposed =float(round((total_buildings_exposed / total_buildings_in_barrios) *100, 1))# Top 5 barrios por exposición a peligro altotop_5_barrios_alta = ( resultado_exposicion_barrio[ (resultado_exposicion_barrio["peligrosidad"] =="alta") & (resultado_exposicion_barrio["nombre_barrio"] !="Sin Nombre") ] .groupby("nombre_barrio")["edificios_expuestos"] .sum() .reset_index() .sort_values("edificios_expuestos", ascending=False) .head(5) .merge( buildings_with_barrios.groupby("nombre_barrio").size().reset_index(name="total_edificios_barrio"), on="nombre_barrio" ) .assign(porcentaje=lambda x: (x["edificios_expuestos"] / x["total_edificios_barrio"] *100).round(1).astype(float)))# Top 5 cuencas con desglose por peligrosidad usando pivottop_5_cuencas = ( resultado_exposicion_cuenca .pivot_table( index="Cuenca", columns="peligrosidad", values="edificios_expuestos", aggfunc="sum", fill_value=0 ) .reset_index() .assign(edificios_expuestos_total=lambda x: x["alta"] + x["media"]) .rename(columns={"alta": "edificios_expuestos_alta", "media": "edificios_expuestos_media"}) .merge( total_edificios_cuenca, on="Cuenca" ) .sort_values("edificios_expuestos_total", ascending=False) .head(5))
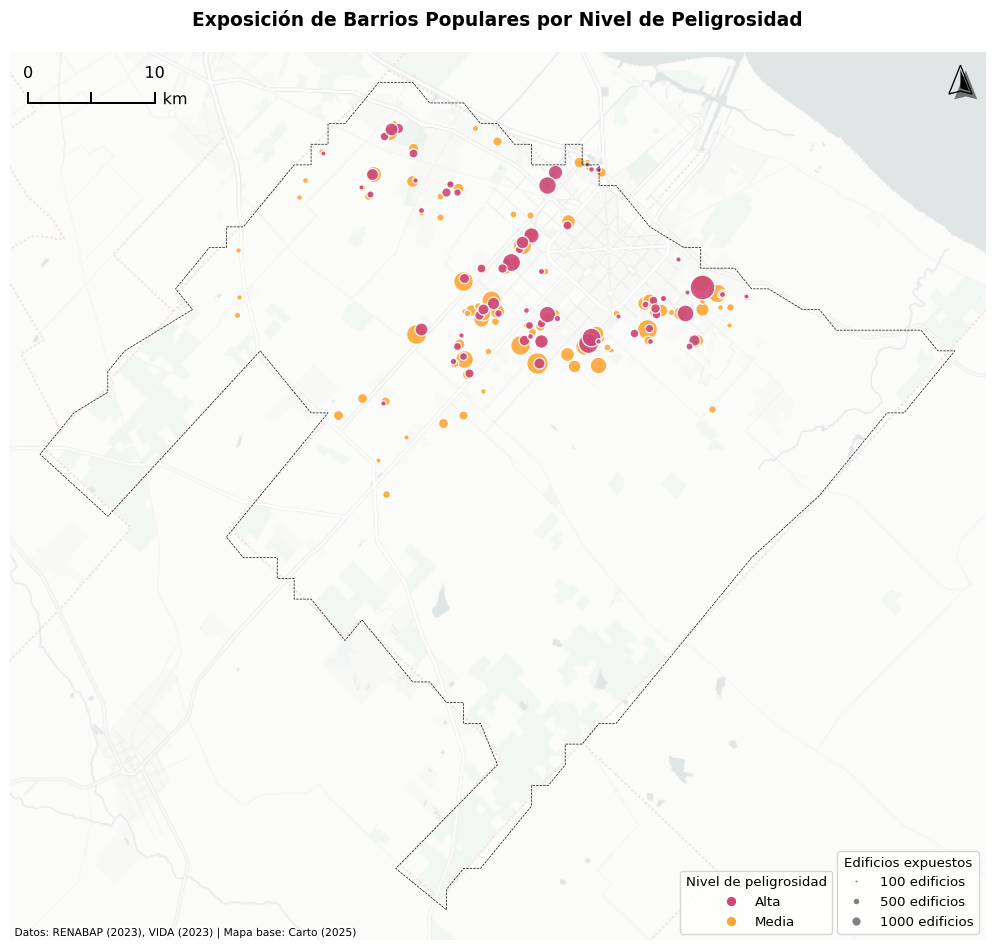
En los barrios populares de La Plata el análisis realizado identifica 17.014 edificaciones o techos expuestos a peligro de inundación bajo el escenario de precipitación máxima probable (PMP), lo que representa el 23,5% del total de edificaciones o techos en barrios populares. De ellos, 6.112 se encuentran en zonas de peligro alto y 10.902 en zonas de peligro medio.
La exposición en barrios populares se concentra principalmente en los alrededores del casco urbano de La Plata. Villa Montoro lidera con 669 edificaciones o techos expuestos a peligro alto (21,7% del barrio), seguido por La Esperanza con 440 edificaciones (16,3%), Las Palmeras con 417 (33,7%), Toba con 335 (67,7%), y La Isla con 320 edificaciones (96,4%).
A nivel de cuencas hidrográficas, Cuenca Arroyo del Gato concentra la mayor exposición con 7.943 edificaciones o techos expuestos (23,0% del total de edificaciones en barrios populares de la cuenca; 2.662 a peligro alto y 5.281 a peligro medio), principalmente debido a la presencia de Villa Montoro y otros barrios populares importantes. Le sigue Cuenca A° Maldonado con 3.316 edificaciones o techos (18,9% del total; 1.000 alta, 2.316 media) y Cuenca Arroyo Martín-Carnaval con 1.096 edificaciones o techos (49,1% del total; 368 alta, 728 media).
4.6.1 Comparación metodológica
Una comparación entre el enfoque tradicional de interpolación areal (basado en datos RENABAP) y nuestro análisis a nivel de edificación o techo revela diferencias significativas en las estimaciones de exposición. Utilizando interpolación areal, donde se asume que las familias se distribuyen uniformemente en los barrios populares, se estima que 8.913 familias estarían expuestas a peligros de inundación (26,3% del total de familias según RENABAP), con 2.948 familias en zonas de peligro alto y 5.964 en zonas de peligro medio.
En contraste, nuestro análisis de edificaciones identifica 18.715 familias expuestas (23,5% del total de familias según nuestro análisis), representando 6.723 familias en peligro alto y 11.992 en peligro medio. Esta diferencia se debe principalmente a la identificación de aproximadamente el doble de viviendas en Barrios Populares de lo que sugieren los datos oficiales del RENABAP.
Aunque nuestro método identifica más familias expuestas en total, la proporción de exposición es menor (23,5% vs 26,3%) que con la interpolación areal anterior, demostrando que el método antiguo sobreestimaba la exposición al asumir distribución uniforme de población. Nuestro enfoque más preciso espacialmente identifica más edificaciones pero calcula menor exposición proporcional debido a su mayor exactitud. Esto resulta en estimaciones más confiables tanto del número total como de la ubicación específica de viviendas en zonas de peligro.
4.6.2 Exposición por barrio
Mostrar código
# Crear el mapafig, ax = plt.subplots(figsize=DEFAULT_FIGSIZE)# Configurar límitesbounds = la_plata_3857.total_boundsmargin =2000# metrosax.set_xlim(bounds[0] - margin, bounds[2] + margin)ax.set_ylim(bounds[1] - margin, bounds[3] + margin)# Agregar basemap de contextilycx.add_basemap( ax, crs=WEB_MERCATOR_CRS, source=cx.providers.CartoDB.PositronNoLabels, alpha=0.7, attribution="Datos: RENABAP (2023), VIDA (2023) | Mapa base: Carto (2025)")# Plot de puntos con jitternp.random.seed(42)plotting_order = ["media", "alta"]for peligrosidad in plotting_order: level_data = exposure_gdf_3857[exposure_gdf_3857["peligrosidad"] == peligrosidad]for _, row in level_data.iterrows(): centroid = row["geometry"].centroid jitter_x = np.random.uniform(-200, 200) jitter_y = np.random.uniform(-200, 200) x_pos = centroid.x + jitter_x y_pos = centroid.y + jitter_y color = PELIGROSIDAD_COLORS[row["peligrosidad"]] size =max(10, row["edificios_expuestos"] *0.5+15) ax.scatter( x_pos, y_pos, s=size, color=color, alpha=0.9, edgecolors="white", linewidth=1.0, )# Leyenda de peligrosidadlegend_elements_peligro = [ plt.Line2D( [0], [0], marker="o", color="w", markerfacecolor=PELIGROSIDAD_COLORS["alta"], markersize=8, label="Alta", ), plt.Line2D( [0], [0], marker="o", color="w", markerfacecolor=PELIGROSIDAD_COLORS["media"], markersize=8, label="Media", ),]# Leyenda de tamañobuilding_values = [100, 500, 1000]legend_elements_size = []for val in building_values: size =max(10, val *0.5+15) legend_elements_size.append( plt.Line2D( [0], [0], marker="o", color="w", markerfacecolor="gray", markersize=np.sqrt(size /10), label=f"{val} edificios", ) )# Crear leyendas lado a lado en bottom rightlegend1 = ax.legend( handles=legend_elements_peligro, title="Nivel de peligrosidad", loc="lower right", bbox_to_anchor=(0.85, 0),)ax.add_artist(legend1)legend2 = ax.legend( handles=legend_elements_size, title="Edificios expuestos", loc="lower right", bbox_to_anchor=(1.0, 0),)add_boundary_outline(ax, la_plata_3857)# Agregar escala y flecha norte para consistenciaadd_scale_bar_and_north_arrow(ax, length=0.20)# Limpiar el mapa - quitar bordes, ticks, etc.ax.set_title("Exposición de Barrios Populares por Nivel de Peligrosidad", fontsize=14, fontweight="bold", pad=20,)ax.set_axis_off()plt.tight_layout()plt.show()# Crear el gráfico de barrasfig, ax = plt.subplots(figsize=(12, 8))x = np.arange(len(barrios_combined))width =0.35bars1 = ax.bar( x - width /2, barrios_combined["edificios_expuestos_alta"], width, label="Peligro Alto", color=PELIGROSIDAD_COLORS["alta"],)bars2 = ax.bar( x + width /2, barrios_combined["edificios_expuestos_media"], width, label="Peligro Medio", color=PELIGROSIDAD_COLORS["media"],)ax.set_xlabel("Barrios", fontsize=12)ax.set_ylabel("Edificios Expuestos", fontsize=12)ax.set_title("Top 10 Barrios por Edificios Expuestos", fontsize=14, fontweight="bold")ax.set_xticks(x)ax.set_xticklabels(barrios_combined["nombre_barrio"], rotation=45, ha="right")ax.legend(loc="upper right")# Agregar valores en las barrasfor bar in bars1: height = bar.get_height()if height >0: ax.text( bar.get_x() + bar.get_width() /2.0, height +5,f"{int(height)}", ha="center", va="bottom", fontsize=10, )for bar in bars2: height = bar.get_height()if height >0: ax.text( bar.get_x() + bar.get_width() /2.0, height +5,f"{int(height)}", ha="center", va="bottom", fontsize=10, )plt.tight_layout()plt.show()show(resultado_exposicion_barrio)
(a) Mapa de exposición de barrios populares por nivel de peligrosidad de inundación
(b)
Loading ITables v2.4.4 from the internet...
(need help?)
(c)
Figure 4.5
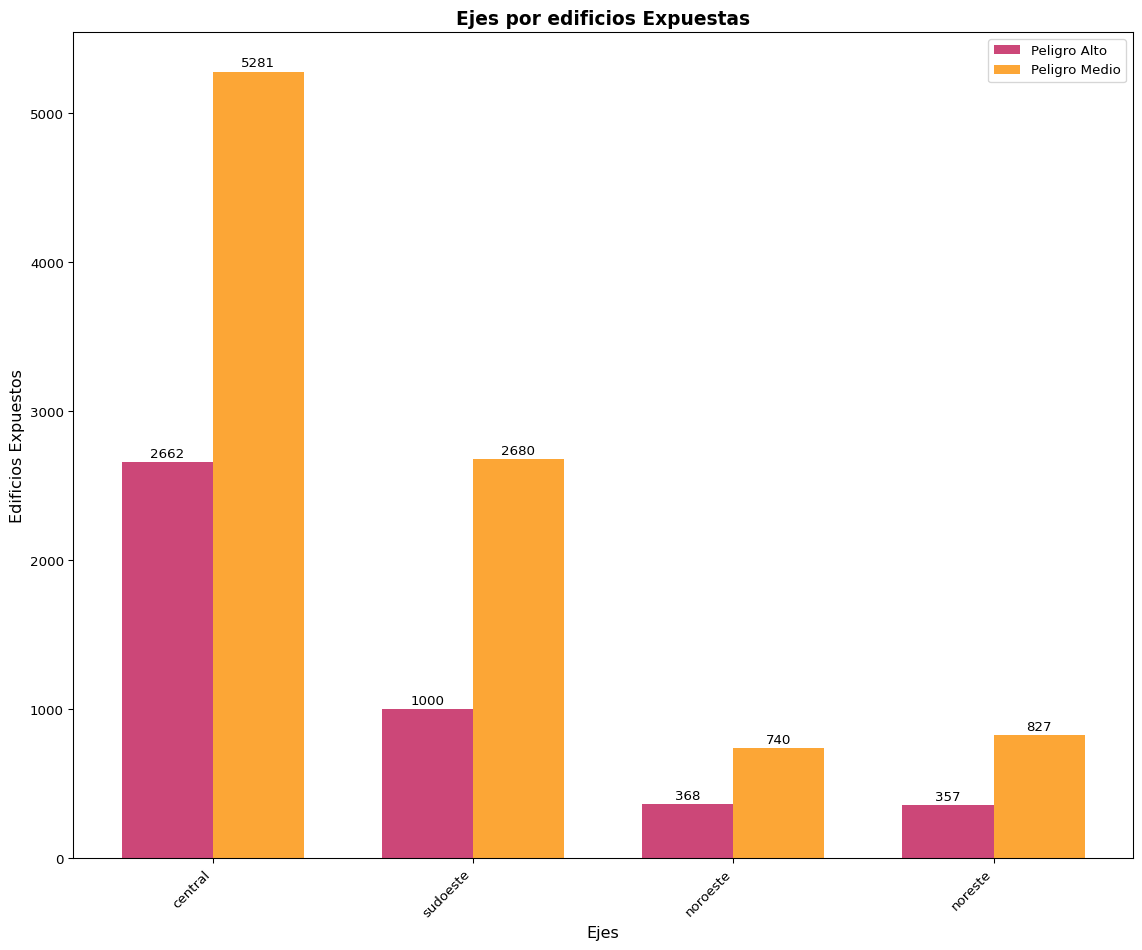
4.6.3 Exposición por cuenca y eje
Mostrar código
# Crear gráfico de cuencasfig1, ax1 = plt.subplots(figsize=DEFAULT_FIGSIZE)x = np.arange(len(cuenca_combined))width =0.35bars1 = ax1.bar( x - width /2, cuenca_combined["edificios_expuestos_alta"], width, label="Peligro Alto", color=PELIGROSIDAD_COLORS["alta"],)bars2 = ax1.bar( x + width /2, cuenca_combined["edificios_expuestos_media"], width, label="Peligro Medio", color=PELIGROSIDAD_COLORS["media"],)ax1.set_xlabel("Cuencas", fontsize=12)ax1.set_ylabel("Edificios Expuestos", fontsize=12)ax1.set_title("Cuencas por edificios Expuestas", fontsize=14, fontweight="bold")ax1.set_xticks(x)ax1.set_xticklabels(cuenca_combined["Cuenca"], rotation=45, ha="right")ax1.legend(loc="upper right")# Agregar valores en las barrasfor bar in bars1: height = bar.get_height()if height >0: ax1.text( bar.get_x() + bar.get_width() /2.0, height +20,f"{int(height)}", ha="center", va="bottom", fontsize=10, )for bar in bars2: height = bar.get_height()if height >0: ax1.text( bar.get_x() + bar.get_width() /2.0, height +20,f"{int(height)}", ha="center", va="bottom", fontsize=10, )plt.tight_layout()plt.show()# Crear gráfico de ejesfig2, ax2 = plt.subplots(figsize=DEFAULT_FIGSIZE)x = np.arange(len(eje_combined))width =0.35bars1 = ax2.bar( x - width /2, eje_combined["edificios_expuestos_alta"], width, label="Peligro Alto", color=PELIGROSIDAD_COLORS["alta"],)bars2 = ax2.bar( x + width /2, eje_combined["edificios_expuestos_media"], width, label="Peligro Medio", color=PELIGROSIDAD_COLORS["media"],)ax2.set_xlabel("Ejes", fontsize=12)ax2.set_ylabel("Edificios Expuestos", fontsize=12)ax2.set_title("Ejes por edificios Expuestas", fontsize=14, fontweight="bold")ax2.set_xticks(x)ax2.set_xticklabels(eje_combined["eje"], rotation=45, ha="right")ax2.legend(loc="upper right")# Agregar valores en las barrasfor bar in bars1: height = bar.get_height()if height >0: ax2.text( bar.get_x() + bar.get_width() /2.0, height +10,f"{int(height)}", ha="center", va="bottom", fontsize=10, )for bar in bars2: height = bar.get_height()if height >0: ax2.text( bar.get_x() + bar.get_width() /2.0, height +10,f"{int(height)}", ha="center", va="bottom", fontsize=10, )plt.tight_layout()plt.show()
(a) Cuencas por edificios expuestas
(b) Ejes por edificios expuestas
Figure 4.6: Exposición por cuencas hidrográficas y ejes territoriales
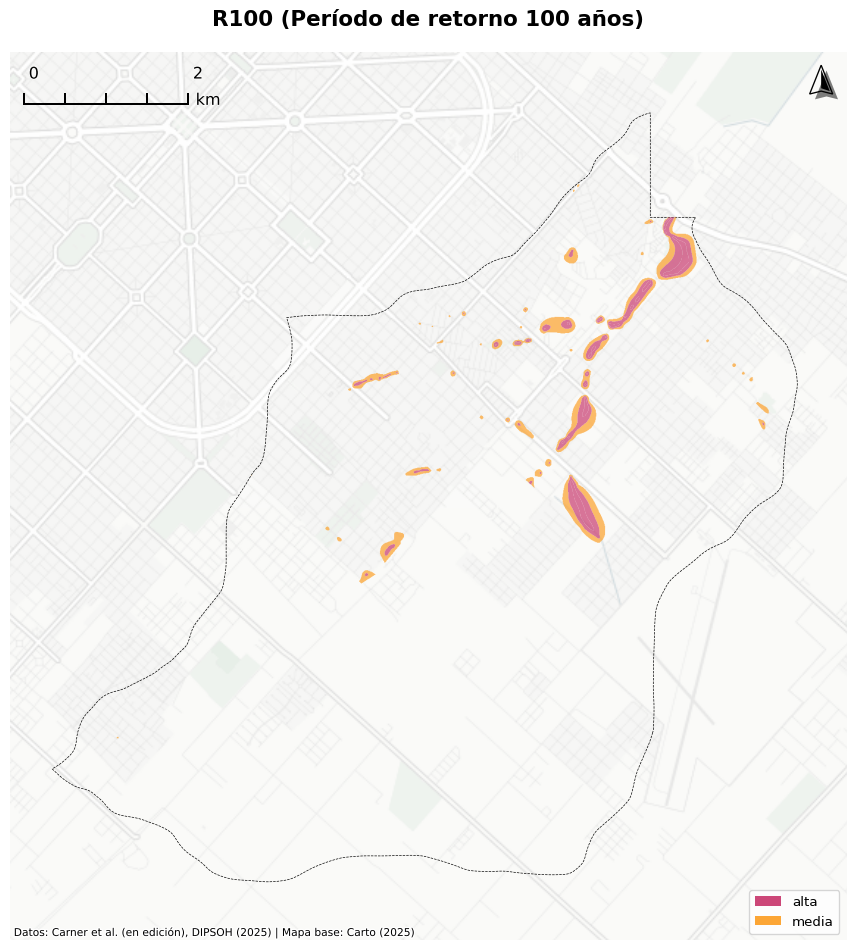
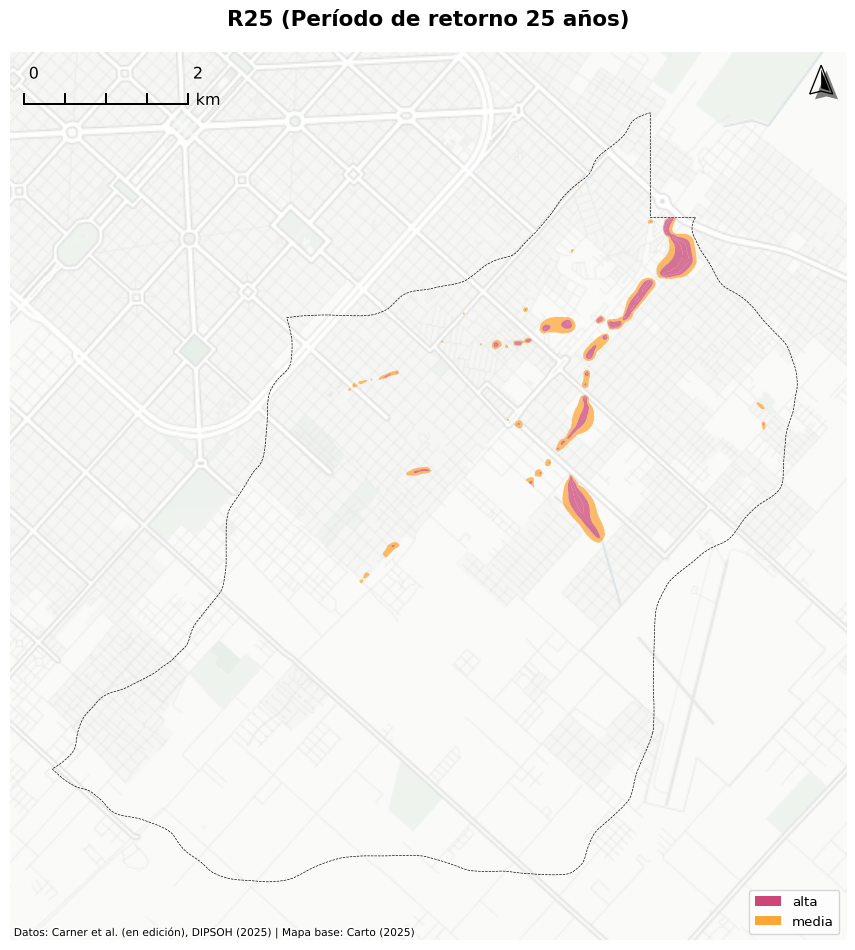
4.6.4 Comparación de periodos de retorno
La implementación de diferentes políticas de gestión de riesgo debería depender de la evaluación del potencial de exposición, y el escenario de PMP utilizado para el PRRI se considera que no necesariamente es el adecuado de utilizar para todas las políticas públicas.
Un ejemplo posible a estudiar, es el caso de la política pública que propone la relocalización de viviendas en zonas de peligro alto y medio. En este análisis, hemos identificado diferencias significativas entre la exposición de edificaciones dependiendo de si se utiliza el escenario PMP, el período de retorno de 25 años o el período de retorno de 100 años para calcular el riesgo (Carner, Ortiz, and Lacunza en edición).
Figure 4.7: Escenarios de peligrosidad en Cuenca Maldonado
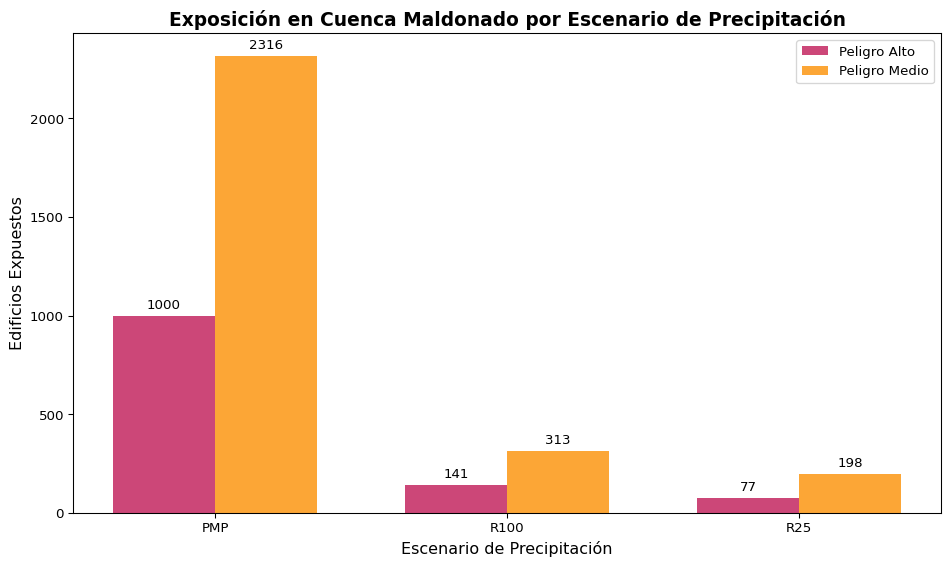
Nuestro análisis de exposición a nivel de edificaciones o techos en la Cuenca Maldonado bajo los diversos períodos de retorno, muestra el impacto del período de retorno elegido sobre la población expuesta calculada. Bajo el escenario de PMP, observamos 1.000 edificaciones expuestas a peligro alto y 2.316 edificaciones expuestas a peligro medio. Mientras que con un período de retorno de 100 años, encontramos 141 edificaciones en peligro alto y 313 en peligro medio, y ante un período de retorno de 25 años se identifican 77 edificaciones en peligro alto y 198 en peligro medio. En términos comparativos, la exposición para peligro alto frente al escenario de recurrencia de la PMP es 7.1 veces mayor en relación con una recurrencia R100 y 13.0 veces mayor frente a una recurrencia R25.
Mostrar código
x = np.arange(len(escenarios))width =0.35fig, ax = plt.subplots(figsize=(10, 6))bars1 = ax.bar( x - width /2, alta_values, width, label="Peligro Alto", color=PELIGROSIDAD_COLORS["alta"],)bars2 = ax.bar( x + width /2, media_values, width, label="Peligro Medio", color=PELIGROSIDAD_COLORS["media"],)ax.set_xlabel("Escenario de Precipitación", fontsize=12)ax.set_ylabel("Edificios Expuestos", fontsize=12)ax.set_title("Exposición en Cuenca Maldonado por Escenario de Precipitación", fontsize=14, fontweight="bold",)ax.set_xticks(x)ax.set_xticklabels(escenarios)ax.legend(loc="upper right")def add_value_labels(bars):for bar in bars: height = bar.get_height()if height >0: ax.text( bar.get_x() + bar.get_width() /2.0, height +20,f"{int(height)}", ha="center", va="bottom", fontsize=10, )add_value_labels(bars1)add_value_labels(bars2)plt.tight_layout()plt.show()
Carner, José Luis, Facundo Ortiz, and Esteban Lacunza. en edición. “Inundaciones y Resiliencia En Territorios Urbanos Fragmentados. Cuenca Del Arroyo Maldonado. La Plata, Argentina.” In, edited by Juan Carlos Etulain. La Plata, Argentina: Editorial UNLP.
Etulaín, Juan Carlos, dir. 2023. “Construyendo Resiliencia. Modelizacion Hidrológica y Elaboración Socio-Ambiental de Medidas NO Estructurales. Caso: Cuenca Del Arroyo Maldonado. Partido de La Plata. Argentina.” Universidad Nacional de La Plata. Centro de Investigaciones Urbanas y Territoriales (CIUT). https://ciut.fau.unlp.edu.ar/investigacion/proyectos-en-ejecucion/.
Romanazzi, Pablo Gustavo, Lucas Mena, and Stefanía Valinoti. 2023. “Plan de Reducción Del Riesgo Por Inundación Para La Región de La Plata (Etapa 2): Protocolos Barriales - Versión 2023.” In. La Plata, Argentina: Universidad Nacional de La Plata. Facultad de Ingeniería; Municipalidad de La Plata; Universidad Nacional de La Plata. Facultad de Humanidades y Ciencias de la Educación. https://repositoriosdigitales.mincyt.gob.ar/vufind/Record/SEDICI_ef9555f5bdb342e7f5f7d7f0f3077a2f.
Smith, A., P. D. Bates, O. Wing, et al. 2019. “New Estimates of Flood Exposure in Developing Countries Using High-Resolution Population Data.”Nature Communications 10: 1814. https://doi.org/10.1038/s41467-019-09282-y.
Los barrios que forman parte, son aquellos “denominados villas, asentamientos y urbanizaciones informales que presentan diferentes grados de precariedad. Deben ser un mínimo de ocho familias agrupadas o contiguas en donde más de la mitad de sus habitantes no cuenten con título de propiedad del suelo ni acceso formal de dos servicios básicos (luz, agua, cloaca).”↩︎